Last time, I introduced a new concept, Iterable, and showed how it solved many of the problems with pair-of-iterator-style ranges. This time around, I’m going to extend Iterable in small ways to make programming with infinite ranges safer and more efficient. Disclaimer: The ideas in this post are more speculative than in the previous three. I’m looking forward to the discussion.
Quick Recap
Previously I described the problems that crop up when representing infinite and delimited ranges with pairs of iterators, the first three of which are:
- Iteration is slow
- The ranges are forced to model a weaker concept than they could otherwise
- Their implementations are awkward
My solution to that problem is the Iterable concept; that is, to allow the end of the range to have a different type than the beginning of the range. Once you allow that:
- Performance is improved because sentinel-ness is encoded in the C++ type system and so doesn’t need to be check at runtime.
- The concept a range can model is no longer limited by the concept that can be modeled by the sentinel, which by its very definition cannot be decremented or dereferenced.
- Since sentinel-ness is now a compile-time property and does not need to be explicitly checked, the logic of iterator comparisons is simpler.
There were two more issues that crop up with infinite ranges in particular. They are:
- Some STL algorithm just don’t work with infinite ranges
- Infinite or possibly-infinite ranges will overflow their
difference_type
These are the issues I’ll focus on in this post.
Infinite Iterables
iota_range is an infinite ranges of integers, starting at some value and counting up, forever. (Suppose that iota_range uses an infinite-precision integer type, so it really never ends.) It is a sorted forward range. Binary search algorithms work with sorted forward ranges, so they should work with iota_range, right? Wrong! You can’t conquer infinity by dividing it. (You can quote me on that.)
Can we make the standard algorithms safer, so the algorithms that don’t work with infinite ranges fail to compile if you pass them one? In the current formulation of the STL the answer is no. There’s no way, given two iterators of the same type, to tell at compile time if they denote an infinite range. Think about it for a minute: the following is perfectly ok, and guaranteed to finish:
// OK, this finishes quickly
iota_range<bigint> rng;
auto i = std::lower_bound(rng.begin(),
std::next(rng.begin(), 10),
5);
But the following will run forever:
// Oops! this runs forever. :'-(
iota_range<bigint> rng;
auto i = std::lower_bound(rng.begin(),
rng.end(),
5);
If rng.begin() is the same type as rng.end(), those two calls resolve to the same instantiation of lower_bound. There’s no way for lower_bound to tell whether it’s going to run forever or not. But if we allow the sentinel type to be different, it opens the door to greater compile-time checking. How? Suppose we had a type function (aka a metafunction) called DenotesInfiniteSequence that takes a type pair (BeginType, EndType) and says whether the sequence is infinite or not. We’ve already established that if BeginType and EndType are the same, DenotesInfiniteSequence has to always return false since it can’t know. But if they’re different — say, if EndType is a special type called unreachable_sentinel or something — then we can know at compile-time that the sequence is infinite.
So the Iterable concept naturally give us a way to test for infinite ranges, right? Well…
Infinite Ranges
Some ranges might genuinely be infinite even though their begin and end iterators have the same type. We want to catch those, too. Consider:
// An infinite range of zeros
class zeros : public range_facade<zeros>
{
friend range_core_access;
struct impl
{
bool sentinel;
int current() const { return 0; }
void next() {}
bool equal(impl that) const
{ return sentinel == that.sentinel; }
};
// begin() and end() are implemented by range_facade
// in terms of begin_impl and end_impl. They will
// have the same type.
impl begin_impl() const { return {false}; }
impl end_impl() const { return {true}; }
};
// zeros models the Range concept
CONCEPT_ASSERT(Range<zeros>());
int main()
{
// Oops! This will run forever.
for_each(zeros(), [](int i) {/*...*/});
}
We’d like to be able to catch mistakes like this if it’s possible, but clearly, the binary DenotesInfiniteSequence type function we hypothesized above isn’t up to the task. For zeros, the types BeginType and EndType are the same, so DenotesInfiniteSequence would return false. And yet zeros is infinite.
So instead of a DenotesInfiniteSequence type function that takes a (BeginType,EndType) pair, let’s have a unary IsInfinite type function that takes a range type. What could be simpler? In code, it would be a type trait:
// Report whether an Iterable is infinite or not
template<typename Iterable>
struct is_infinite
: std::integral_constant<bool, true-or-false>
{};
This type trait can be used to define a concept FiniteIterable as follows:
// Current proposed Concept Lite syntax
template<typename T>
concept bool FiniteIterable =
Iterable<T> && !is_infinite<T>::value;
(Why FiniteIterable instead of InfiniteIterable? I’ll say why in a minute.) Every FiniteIterable is an Iterable. In fact, there’s a parallel refinement hierarchy here, just as there is with Ranges:
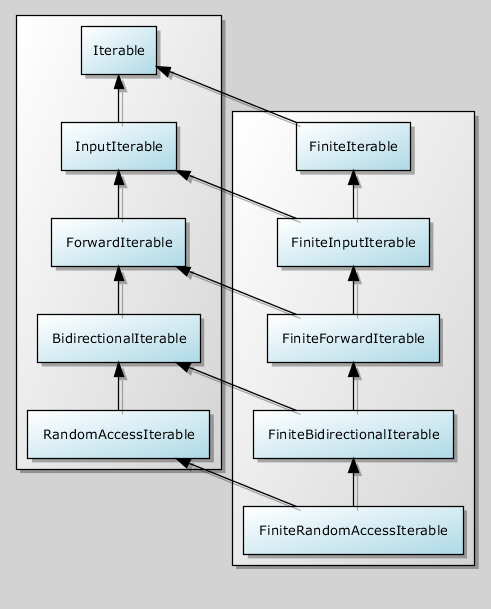
Finite Iterable Concept Hierarchy
And as with Range, we don’t actually need to define all these concepts in code. “Finite-ness” is orthogonal to the Iterable concept hierarchy and can be queried separately.
So why FiniteIterable instead of InfiniteIterable? It comes down to the algorithms and their requirements. There are no algorithms that require that their range arguments be infinite. So being able to say requires InfiniteIterable<T> is useless. But an algorithm like lower_bound would very much like to require that the range it’s operating on has a definite end; hence FiniteIterable.
Now, all iterable things model FiniteIterable by default, and a type has to opt in to being infinite. How? One way is to specialize is_infinite. As a convenience, the utilities for building iterables and ranges take an optional IsInfinite template parameter, so opting in is easy. Here’s how zeros looks now:
// An infinite range of zeros
class zeros : public range_facade<zeros, true>
{ // ... IsInfinite ...................^^^^
// ... as before ...
};
// zeros is a Range but it's not Finite
CONCEPT_ASSERT(Range<zeros>());
CONCEPT_ASSERT(!FiniteIterable<zeros>());
With the addition of the FiniteIterable concept, the algorithms that require finite-ness have an easy way to check for it at compile-time. This is only possible with a range-based interface, so we can add that to the long list of advantages ranges have over iterators.
Possibly Infinite Ranges
Once we have a way to separate the finite ranges from the infinite, we now have to categorize the ranges. This should be simple; either a range is finite or it’s not, right? It’s actually trickier than that. Take an istream range, for instance. It might be infinite, or it might not. You don’t know. Most of the time, the stream runs dry eventually and the iteration stops. In fact, almost all the time. But sometimes…
This is a sticky situation. Should we be prevented from passing an istream range to an algorithm just because it might go on forever? I think the answer is yes, but I confess I haven’t made up my mind about that yet. I think we need more real-world usage.
Counting the Uncountable
With infinite ranges, we run into an inherent difficulty: all iterators — and by extension, all iterables — have an associated difference_type. Alex Stepanov has this to say about an iterator’s difference_type:
DistanceTypereturns an integer type large enough to measure any sequence of applications of successor allowable for the type. 1
Since an iterator over an infinite sequence permits an infinite number of applications of successor, we need an integer type large enough … well, infinitely large. Does this problem have a solution? As in the words of Tevye from Fiddler on the Roof, “I’ll tell you…. I don’t know.”
No flash of insight has been forthcoming. Instead, here’s a core dump of my brain on the issue:
- C++ needs
bigint, an infinite-precision integral type. Other languages have it. C++ is a great language for building libraries, and this is crying out for a library solution. If such a type existed, an infinite range might choose that as itsdifference_type. That would come with a not-insignificant performance hit. - Infinite ranges could use
safe_intas itsdifference_type.safe_intbehaves like anint, but it can represent infinity. Instead of overflowing and going into undefined-behavior-land, asafe_intclips to infinity and stays there. The two biggest problems with letting an iterator’sdifference_typeoverflow are undefined behavior and the inability to tell after the fact if anything went wrong. Withsafe_int, you can avoid the UB and have a way to tell at runtime if something bad happened. That might be enough in some situations. If this feels like a Big Hack to you, that’s because it is. - An alternate design of
safe_intmight be to throw an exception on overflow rather than clip to infinity. That might be appropriate in some situations. - Another approach is to look at where the library uses
difference_typeand give users a way to specify that a different type be used. For instance, the API of a range-baseddistancealgorithm might take a range and optionally a starting count. It would default todifference_type{0}, but if you passed in, say, abigintthen you’re opting in to safer, slower code. - You can ignore the problem. Users that worry about overflow can use a
counted range adaptorto make sure iteration stops before thedifference_typeoverflows. - Something else I haven’t thought of.
Here’s my opinion: I don’t like anything that introduces unnecessary runtime overhead, so std::ptrdiff_t is an acceptable default for difference_type. In addition, we should design range-based interfaces in such a way as to give users a way to specify a different difference_type when overflow is a concern. So basically, I’m going with options (4) and (5). The other library types — bigint and maybe a policy-based safe_int — would be nice-to-haves that users could pass to these algorithms to get the safety/speed tradeoff that makes sense for them.
That’s the best I’ve got.
Summary, and Next Steps
Maybe after the first 3 posts about range concepts you were feeling good, like it’s all falling into place, and now you’re kind of confused. But I think we’re in a good place, much better than we were. I described 5 problems with pair-of-iterator ranges. A new concept — Iterable — addresses 3 of them very well (slow iteration, modeling weaker-than-necessary concepts, awkward implementations). The 4th problem (infinite ranges) we can address with a further refinement of Iterable. And we have some options for dealing with the 5th (overflow), which is helped by being able to tell the infinite ranges apart from the finite ones. So the new concepts help there too. I think this is a promising start.
Some of you have asked if I’m planning to take these ideas to the C++ standardization committee. Indeed, I am. When we get language support for concepts (not if, when), there is very likely to be a push for a new, concept-ified version of the STL, probably in a different namespace. This wholesale rewrite is a prime opportunity for getting something like Iterable baked into the STL from day one.
My next step is to start a discussion on the SG9 (Ranges) mailing list. It’s likely to be contentious, and I expect these ideas will evolve. Consider subscribing to the list and joining the discussion.
Addendum
Sean Parent has commented on my blog and made an interesting point about the importance of counted algorithms (e.g. copy_n). He’s challenged me to find a more efficient way of supporting counted ranges than my proposed solution. I have some initial thoughts on the issue that I’ll write up and publish here provided they pan out. At any rate, it’s clear that it’s time for brains other than mine to be working on this problem. C++17 is closer than you might think, and time’s a’wasting!
1. Stepanov, A; McJones, P. Elements of Programming. Addison-Wesley. 2009.↩
Hi Eric,
You raise some very interesting points here, and sentinels definitely solve some of the problems of iterators.
You may be aware that my C++Now14 talk about various range approaches got accepted, so I’ll be talking about this at the conference. I would like to incorporate some of the points you made in this article series, with your permission.
Anyway, while this approach solves some of the problems of iterators, there are of course others that are left unsolved, mainly the issue of implementing iteration adapters that need to know their own end. filter_iterator needs to skip elements but mustn’t jump beyond the end. concat_iterator needs to check whether it has reached the end of one range and must start the next – and don’t get me started on bidirectional concat_iterators – you get to store three iterators for every subrange.
Certainly.
I’ve found that once you have ranges, some of these problems are solved by having the iterators keep a pointer back to their range.
My
join_range‘s iterators store a pointer back to the range and a tagged union of the two joined ranges’ iterators. Disclaimer: I haven’t benchmarked its performance, but it works with bidirectional and random-access ranges.I think that a good approach here, and it´s an improvement I also would like to see for algorithms that hava as a precondition to be sorted (lower_bound, for example) is to make the user assert a property.
If you have a possibly infinite range, do something in the lines of:
istream_range<string> my_input_range...;//Creates wrapper range that returns is_infinite trait as false
all_of(not_infinite(my_input_range), bind(less<>(), 0, _1));
For sorted ranges I would like something to assert the precondition of ordering in some way, same style as the assertion above. It would make it way safer to use.
That’s not an unreasonable approach for infinite ranges. For sorted sequences, it feels like a bit too much hand-holding. I can’t really say why it feels ok in one case but not the other.
Sorry, I saw I meant:
//By default input range returns is_infinite trait as true
istream_iterator<int> my_input_range;
What would be the consequence of just not allowing infinite ranges to have a difference_type?
I thought about that. There are a couple of problems. There are perfectly reasonable things an algorithm might want to do with the
difference_typeof an infinite range. E.g. return the offset at which at which a predicate becomes true. An algorithm like that needs to declare its return type. If an infinite range doesn’t have adifference_type, what should it choose?Or maybe the algorithm operates on a sliding window of the range. The range is infinite, but the window is finite. Knowing the
difference_typecould be handy there, too.It’s also problematic from the standpoint of the concept hierarchy. Iterables have a
difference_type. If an InfiniteIterable doesn’t, it doesn’t refine Iterable. That’s fixable by changing the hierarchy. I haven’t investigated the implications since the problems above seem pretty damning to me. But maybe they aren’t. I dunno.I have much sympathy for the idea that a non-Limited Iterable should not have a
difference_typebecause even though a non-Limited counter type could be devised, the programmer would have to worry about performance implications. Without it, if it typechecks, there is no issue.So, shooting from the hip… Have the base Iterable not include
difference_type(presumably many interesting algorithms continue to work with that), then add concepts of increasing strength: Measured (addsdifference_type), Finite, and Bounded (a Bounded Iterable is a Range, presumably).One more thing, I sure wish Iterable were named Range instead (I don’t have issues with the possibility of a range not being finite, and Iterable doesn’t roll off the tongue…).
What do you think?
Never mind my suggestion about renaming Iterable to Range; that’s a thinko. (I suspect my tongue will get used to Iterable quickly enough.)
Thanks, Daveed. It probably makes sense to go through the algorithms and figure out which ones need Limited Iterables and which don’t. It’s possible that very few actually use
difference_type, and that those algorithm just don’t work with infinite ranges. We could then redefine the concept hierarchy the way you suggest.I picked the term “Iterable” since it’s new and doesn’t come with baggage. “Range” is a term of art and is used all over the standard already, where it means something specific.
I’ve never like Range, because we are only talking about ranges of countable (ie iterable) sets. (Countable means 1-to-1 with the set of integers – ie each element of the set can be given a number. So the set can still be infinite, but not more infinite than the integers. Math integers, not C++ integers. Anyhow…)
The set of reals between 0 and 1 is also a range. But it is not iterable – you can’t give me the next real after 0. (Unless you go down some odd branches of math that have defined 0+ and things like that….)
So I’d like to avoid Range, if possible. Or call it CountableRange, but that doesn’t roll off the tongue nor give any obvious benefit. Iterable does expose its important property. (SG9 uses traversable, I think.)
I read the series and my intuition is the same, which is that difference_type isn’t something that should be defined on an infinite range.
To ease the pain of that however, I would suggest that infinite iterables can be converted to finite iterables via an adaptor. So, I could say:
auto s = std::distance(take(iota_range(), 5));
assert(s == 5); // true only if infinity is greater than 5. 🙂
And here you have a solution for dealing with istream_iterator reading from a network. If you want to count the number of bytes, you do:
std::istream& sin = …;
std::istream_iterable inf_it{sin};
auto fin_it = take(inf_it, std::numeric_limits::max());
std::ptrdiff_t dis = std::distance(fin_it);
Granted, many people think that istream_iterators aren’t infinite in the same sense that iota_ranges are and I’d disagree. iota_ranges should fail/stop when they overflow, since overflowing isn’t monotonically increasing toward infinity and that’s the same even if the type is a bigint, it just happens when memory allocations start failing. So, any infinite range should implement a failure mode that represents it’s end in some way. That would imply that the only distinction between iterables and finite iterables is that finite ones have a difference type and non-finite ones do not, but they all have ending conditions. If you are wondering about how to efficiently tell if a bigint is ‘done’, it is simply a bigint for which the previous operation failed (whether this is represented as ‘infinity’ or throwing an exception).
WordPress ate my <ptrdiff_t>…
And thanks for fixing your feed so that it no longer fails rss validation, granted, you can perhaps fix the warnings here:
http://feedvalidator.org/check.cgi?url=http%3A%2F%2Fericniebler.com%2Ffeed%2F
Or just use it to check if your feed becomes invalid in the future. 🙂
Rats, I thought I fixed those. I wonder if my Markdown plugin is corrupting my RSS feed.
When is a range infinite?
Well, a range maybe is never infinite in itself. The usage is what it says if it can be conceptually infinite, but you will know if it is at the call site. At this moment is when we would calculate the difference_type.
What I mean is:
If the range is infinite or possibly infinite at the call site, difference_type is bigint.
If the user manipulates this range, via some adapter/assertion at the call site he could ssert that the range won´t be bigger than n steps:
//new range with new difference_type
copy(take(infinite_range, 1000), …); //difference_type deduced from that 1000 and range adaptor created
If you are concerned about bigint performance, then just make a compilation error by default and some other means to cancel that compilation error.
Just my two cents.
Is an “infinite range” really a range? By definition, there is no end(). There is only a position which can be incremented freely. To do anything meaningful you always need to specify how far – which may be done with a count, an delimiter, or a position.
I think an infinite range is really only a property of a position, and not even a useful property to encode since I know of no algorithm that relies on “infinite-ness” – it is much the same as an output iterator, for any given algorithm it must be of some finite, sufficient, length.
I don’t think “infinite” is a great term here, since our machines are finite (to the best of our knowledge). However, I do think it’s useful to have a notion of an Iterable that is not programmatically limited (nor, perhaps, measured).
True, but we do know plenty of algorithms that don’t require explicit bounds or even a measure of distance, some that make sense for combinations of limited and non-limited sequences, and adaptors that have natural semantics for non-limited sequences (e.g., zip). Doesn’t that suggest that having matching concepts would be useful?
But I think we do have a matching concept – an iterator. And as an example of an algorithm – see std::transform. For the second range it only takes a single iterator.
Our memory resources are finite, but our running time is infinite, give or take. Thus infinite loops, etc.
In general, maybe unbounded is a better term.
I agree, though most of this stuff is above my head I already complained how infinity is for all I can see syntax sugar… I cant find my comment or it was deleted but basically all I said that zip {it1, it2},{0..}
is a syntax sugar, aka yo could instead of 0.. write 0.. dist(it1,it2) though that might be slow, so lazy range with generator could be solution, like a stateful counter.
You might be right. I guess it depends on a couple of things: (1) What are we to make of the range denoted by two
istream_iterator‘s? It’s unbounded in principle, though often finite in practice. It has a non-trivial end condition, which may or may not ever evaluate to true.Which brings me to (2): What you say is true about eager algorithms, but what about lazy ones? In particular, what about range adaptors, like filter and transform? They work fine with infinite ranges today. I suppose additional adaptors that work on infinite iterators would be one solution (a normal filter iterator wouldn’t do since filter iterators store the end so as not to run past it). A little dirty, but workable.
What about a
ziprange adaptor? Say you want to zip 2, or 3, or N ranges into a tuple. In this case, an infinite range is a very handy thing. The resulting range is as long as the shortest range. Definingzipto take either ranges or iterators (which are assumed to be infinite), might be awkward.Anyway, I’m not wedded to my ideas about infinite ranges. If you know of ways to solve the above problems, or have reasons to think they’re not really problems, I’m all ears.
But I think we do have a matching concept – an iterator. And as an example of an algorithm – see std::transform. For the second range it only takes a single iterator.
I don’t think writing an algorithm such as zip which is bounded to the shortest range, and then passing it items which are unbounded, and letting the compiler optimize out the additional checks knowing they all return false, is a good way to define a concept. This is what I mean by start with the algorithm, write zip that doesn’t have to do the checks for an unbounded iterator. That is what should be defining your concept. In a similar matter to delimited ranges, write the algorithm to call the predicate – I agree with you that inputIterators are not idea, but there isn’t a reason to shoehorn input iterators to have an end iterator, of a different type or not.
With regard to shoehorning input iterators into having an end iterator, I guess that you would prefer input sequences to be represented as a range with a begin position and a predicate for evaluating whether sequence is exhausted, and allowing that to be a range. I think your way and mine are procedurally equivalent, but with a different syntax. I prefer picking a syntax that allows code reuse.
As for whether infinite ranges are sound generic design or not, I’ll leave that to the GP experts. I’ll merely point out that infinite ranges are a fact. They will be easy to create in your lib or mine. We can take advantage of that to make range interfaces simpler and more consistent, or not. The case of
zipis interesting. The options I see are:or:
The usage is either:
or:
I find the former cleaner and more readable. It seems reasonable to me that, when calling a range-based interface, I am required to pass ranges.
With respect to the
difference_typeof an infinite range: I think you might be able to take advantage of your differently-typed sentinels to solve this problem. Consider, for example, a range that models a subset of the positive integers. When a range of this type is finite, e.g. when modelling the interval[42, 343], you can represent it with twointeger_iterators. When the range is infinite, e.g.[1024, infinity), you can represent the range with aninteger_iteratorand anininity_iterator. Here’s where it gets interesting.When you write your difference operator for finite ranges, you can return
intorstd::ptrdiff_tor something similarly appropriate:std::ptrdiff_t operator - (integer_iterator end,
integer_iterator begin)
{
return *end - *begin;
}
Then, you can overload for your sentinel type:
infinity_t operator - (infinity_iterator end,
integer_iterator begin)
{
return {};
}
where
infinity_tis a type which always encodes infinity (or possibly negative infinity, NaN, etc.). You’d have to write a fair amount of boilerplate to wedge it into the integral type conversion sequence so as to make it generic code-friendly, but I think it’s doable.The problem I see with this, and with the typed-sentinel pattern in general, is that it makes it a little more difficult to have range objects. You would (unless I’m grossly mistaken, which is certainly possible) have to choose between representing infinite and finite ranges with separate types, and implementing some kind of type erasure between finite and infinite iterators– which is (isomorphic to) what iterators like
std::istream_iteratordo, and exactly what we want to avoid in the first place.Maybe you could accomplish something with a utility class template to handle type erasure automatically, much like
std::unique_ptrdoes for memory management:template <ForwardIterator I>void my_algorithm (I begin, I end);
// Hey, I can't call this on [0, infinity)!
// So I'll write a wrapper.
template <ForwardIterator I1, ForwardIterator I2>
void my_algorithm (std::union_iterator <I1, I2> begin,
std::union_iterator <I1, I2> end);
This shows the backwards-compatibility application, but one could also use it to eliminate so-called template bloat at the cost of some efficiency.
Heh! You might be interested in this. Basically, I had exactly what you’re suggesting here, but recently took it out since it doesn’t solve the problem of infinite Ranges, where begin and end have the same type.
Also, I’ve been planning to write what you’re calling
union_iteratorfor a while now. It will be part of an adaptor that promotes an Iterable into a Range (with some runtime cost, as you’ve mentioned). This is mostly so that Iterables can be used with code that doesn’t know about them (like range-based for loops, for example).A single iterator also suffices to describe a delimited range if we assume a sentinel of T(0). i.e. a NTBS. Not sure how that should be handled, just thinking out loud.
EoP defines only bounded and counted (weak) ranges (no delimited or infinite). There is a correspondence between bounded algorithms and counted ones but it is not necessarily mechanical. Many pairs have different return types (e.g. for_each vs for_each_n; find_if vs find_if_n) some return plain iterators others – (counted) ranges and yet some other return something else (how would these be dispatched? should they?); for another large group the former is trivially implemented in terms of the later – (e.g. partition_point just calls partition_point_n) and maybe, though I do not know of, there are pairs with totally original implementations.
There are a number of sentinel algorithms (all with ‘unguarded’ suffix) but those are different from the _delimited ones in this series. unguarded shave N comparisons from the base versions (and miss the _end argument of course). I am not familiar with any sentinel algorithm in standard library (the original stl has a few as implementation details: e.g. unguarded_partition, unguarded_linear_insert).
I think it makes sense to make a taxonomy of algorithms (and go well beyond std). Why not start with a subset from http://www.elementsofprogramming.com/code.html? I suspect that ones that make sense to be implemented in terms of delimited ranges would not make an overwhelming set. Even less for the infinite range. Such a ‘blow by blow’ approach may help (at least some of) us understand the value of the delimited and infinite ranges.
This is an insightful comment. Indeed, the issue of return types and values needs to be thought through very carefully. The case of
for_eachandfor_each_nis interesting. Sean Parent has given good reasons why a range-basedfor_eachalgorithm needs to return the new position, in which case the return type offor_eachandfor_each_nis the same.That won’t always be the case, though. I suspect we’ll find a tug of war between returning the minimum amount of information, and returning the same thing for all kinds of ranges, whether positional, counted, or something else. It’s an interesting topic, and I don’t have an answer right now.
Should algorithms that may terminate early (such as find and any_of) work on infinite ranges?
It’s a noble goal to catch at compile time all calls to algorithms that won’t terminate, but it doesn’t seem to be possible in general. Moreover, sometimes calling an algorithm that won’t terminate is exactly what the user wants.
// Infinite range of incoming HTTP requests.
auto requests = ...;
// Infinite range of ip addresses.
auto ip_addrs = requests | transformed(get_ip_addr);
// Write all ip addresses to a database.
copy(ip_addrs, db_output_iterator);
Perhaps this problem isn’t worth solving?
Counted ranges, on the other hand, need a solution. Right now it seems like any multipass algorithm will see a performance hit when passed counted ranges (compared to a hand coded solution that accepts an iterator and an integer separately) due to always incrementing both the iterator and the counter together when incrementing only one of them would be sufficient. If this problem was solved, I would be completely sold.
Sure, there are cases like that. And there are cases where it’s an error 100% of the time, like passing an infinite range to
std::distance. My lib only catches such cases, which at the moment only includestd::distanceand the binary searching algorithms.Agreed 100%. Multi-pass algorithms suffer from this problem as well as any non-counted algorithm that internally dispatches to a counted one, like possibly
std::lower_bound. I have a solution half implemented that I think will address the performance problem as well as solving a dilemma about return types. I’ll announce it here when I’m ready.First comment on your blog Eric. By the way, this is an excellent and very informative article. But I have a question (not that I am not familiar with boost.range). Mathematically, we can provide several opertaions on sets: union, intersection, complement, disjoint union. Is there a place for compound ranges in your current design? (for example a union of two ranges, or an intersection of two ranges)?
These algorithms already exist in the standard library (e.g.
set_union,set_intersection, etc.). My range lib and Boost.Range have range-based versions of them.These algorithms construct a new range from the input ones. Here I am describing something different. Imagine an vector
vof30elements, in which I’ve taken two ranges, for example[std::begin(v)+3, std::begin(v)+10[and[std::begin(v)+15, std::begin(v)+19[. It would be great to be able to generate a “compound” range likecompound = [std::begin(v)+3, std::begin(v)+10[ U [std::begin(v)+15, std::begin(v)+19[with its own iterators so that afor_eachexecuted on that range will be executed on the union/intersection/complement… subranges (sorry for the mixed programming/mathematical notation).Hello Eric. This is a bit offtopic for the post itself. Anyway, it’s related to ranges.
When designing ranges, did you consider dropping _if, _copy, etc. algorithms and providing a smaller interface compared to what the old header offers?
I guess you already know about this, but I say this because of this reference in boost.range documentation:
http://www.boost.org/doc/libs/1_55_0/libs/range/doc/html/range/reference/adaptors/introduction.html
Though I think it’s well known for you already. Maybe it would be a good idea to drop all the things that can be composed out of predicates + push_back, etc, leading to a smaller core. Do you think this would be the correct approach?
The core could be made smaller, it’s true. But I don’t intend to drop any standard algorithms. That would make it needless difficult for people to migrate away from the STL and to a range-based interface.
One comment I have that isn’t paralleled by someone else is that I think that being ‘infinite’ should be a property of the iterator and not the range.
As an aside: I don’t quite know what the difference_type of istream_iterator is supposed to mean, but even ignoring the impossibility of overflowing 64bits worth of ‘stuff’ being read from a stream, I’m still of the view that it is theoretically wrong.
Anyways, I view ranges/iterables as effectively syntactic sugar on top of iterators. This means that something as fundamental as infinite or not should be associated with the iterator rather than the range/iterable, since it’s the more fundamental concept. Perhaps there’s a good reason not to do this?
If we decide that infinite ranges don’t have a difference type, then the iterators of an infinite range can’t have a difference type either. So yeah.